Open-sourcing kernels on the HuggingFace Hub
We (Geometric) are focused on creating the highest-performing kernels possible. Today we’re releasing six of these kernels on the HuggingFace Hub with a commitment to open-source more in the future. The kernel card is available here and can be used via HuggingFace’s kernels library.
Kernels
The six kernels we are releasing include:
- GRPO, BNPO, Reverse KL Forward: compute the GRPO, BNPO, and Reverse KL Forward loss functions. These kernels compute only the forward pass and can be used in validation/testing.
- GRPO, BNPO, Reverse KL Fused Forward+Backward: compute GRPO, BNPO, and Reverse KL with a fused forward and backward pass. These kernels return both the loss and the gradient of the loss, and can be used in training.
All kernels are implemented in CuteDSL and support fp32, fp16, and bf16. They have been profiled on H100 GPUs and should run on Ampere and Blackwell architectures as well.
Our kernels support dynamic batch sizes and sequence lengths. This lets us avoid re-compiling the kernel each time the sequence length changes, which is common in post-training workflows.
Using our kernels
Each kernel family has three variants:
- A pure forward kernel with suffix
_fwd. - A fused forward+backward kernel with suffix
_lossthat returns a tuple(loss, grad). - An autograd-aware wrapper with suffix
_autogradthat returns just the loss but supportsloss.backward(). The autograd-aware wrapper has a noticeable overhead compared to 2, we’ll continue to investigate ways to reduce this overhead in the future.
To use our kernels, install the kernels library and import a kernel module:
# make sure `kernels` is installed: pip install -U kernels
from kernels import get_kernel
kernel_module = get_kernel("Geometric-AI/geometric-ai-kernels")
grpo_loss = kernel_module.grpo_loss_fwd
grpo_loss(...)
Training with our kernels
There are two ways to use our kernels for training:
1) Direct (loss, grad) return - the lowest-overhead path.
The fused forward+backward kernel writes both the scalar loss and the closed-form gradient dL/d(policy_logprobs) in a single CUDA launch. The Python wrapper returns them as a tuple, and the caller chains the gradient into the upstream model:
loss, grad_policy = kernel_module.grpo_loss(
policy_logprobs,
old_policy_logprobs,
ref_logprobs,
advantages,
completions_mask,
)
policy_logprobs.backward(grad_policy)
Note that the returned loss is a plain 0-dim tensor with no autograd graph, so you will need to use the returned grad_policy to backpropagate through the rest of the model. This is the lowest-overhead way to use our kernels for training.
2) Autograd-aware _autograd - drop-in for an eager training loop.
If you want loss.backward() since it’s more compatible with most training libraries, use the _autograd variants. They wrap the same fused kernel as a torch.library custom op with a registered backward:
loss = kernel_module.grpo_loss_autograd(
policy_logprobs,
old_policy_logprobs,
ref_logprobs,
advantages,
completions_mask,
)
loss.backward()
Benchmarking our kernels
In order to ensure a fair comparison of our cute kernels vs torch.compile kernels we investigated two ways of creating fused forward+backward kernels in torch.
Method 1: Using torch.compile with fullgraph=True and torch._dynamo.config.trace_autograd_ops
We set the fullgraph flag in torch.compile to True and enabled torch._dynamo.config.trace_autograd_ops to allow autograd operations to be traced and fused together. This method allows for the creation of fused forward+backward kernels. A fused kernel can then be created as follows:
import torch
torch._dynamo.config.trace_autograd_ops = True
def torch_reverse_kl_div(
student_logits: torch.Tensor,
teacher_logits: torch.Tensor,
completions_mask: torch.Tensor,
) -> torch.Tensor:
"""Plain-Python reverse-KL reference traceable by AOTAutograd / Inductor.
Mirrors ``geo_evo.torch_kernels.torch_reverse_kl_div_baseline``.
Computes ``KL(student || teacher) = sum_v p(v) [log p(v) - log q(v)]``
averaged over valid tokens.
"""
log_p = log_softmax(student_logits, dim=-1)
log_q = log_softmax(teacher_logits, dim=-1)
# ``kl_div(input, target, log_target=True)`` computes
# ``KL(target || input)``, so input=log_q, target=log_p gives
# ``KL(student || teacher)``.
kl = kl_div(log_q, log_p, log_target=True, reduction="none").sum(dim=-1)
n_valid = completions_mask.sum().to(torch.float32)
kl = (kl * completions_mask).sum() / n_valid
return kl.to(student_logits.dtype)
def torch_reverse_kl_div_grad(
student_logits: torch.Tensor,
teacher_logits: torch.Tensor,
completions_mask: torch.Tensor | None = None,
) -> tuple[torch.Tensor, torch.Tensor]:
"""Returns the gradient and loss"""
loss = torch_reverse_kl_div(student_logits, teacher_logits, completions_mask=completions_mask)
(grad_student,) = torch.autograd.grad(loss, [student_logits])
return loss.detach(), grad_student
fused_reverse_kl = torch.compile(torch_reverse_kl_div_grad, fullgraph=True, mode="max-autotune-no-cudagraphs")
Method 2: Writing out the forward and backward ops in a single function
We can also write out the forward and backward pass in a single function. For reverse KL this would look like:
def torch_reverse_kl_div_fwd_bwd(
student_logits: torch.Tensor,
teacher_logits: torch.Tensor,
completions_mask: torch.Tensor,
) -> tuple[torch.Tensor, torch.Tensor]:
"""Run a reverse-KL forward + backward step using only forward ops.
Args:
student_logits: Student logits, shape (N, C, V). ``requires_grad``
is ignored — gradients are computed manually.
teacher_logits: Teacher logits, shape (N, C, V).
completions_mask: Boolean mask of shape (N, C). Pass an all-ones
mask if no tokens are padded.
Returns:
Tuple ``(loss, grad_student_logits)``.
"""
with torch.no_grad():
log_p = log_softmax(student_logits, dim=-1)
log_q = log_softmax(teacher_logits, dim=-1)
p = torch.exp(log_p)
log_diff = log_p - log_q # (N, C, V)
kl_per_tok = (p * log_diff).sum(dim=-1) # (N, C)
# Cast n_valid to fp32 to avoid fp16 overflow when n_valid > 65504.
n_valid = completions_mask.sum().to(torch.float32)
inv_n_fp32 = torch.reciprocal(n_valid)
mask = completions_mask.to(student_logits.dtype)
# Loss aggregates in fp32 (sum_fp16 * inv_n_fp32 promotes to fp32);
# grad uses the low-precision reciprocal so the per-tok elementwise
# stays in the input dtype.
loss = (kl_per_tok * mask).sum() * inv_n_fp32
inv_n = inv_n_fp32.to(student_logits.dtype)
# Per-token gradient: p_k * (log_p_k - log_q_k - kl). Broadcast kl
# over the vocab dim. The +1 terms from differentiating sum_v p_v
# cancel, so no constant offset appears here.
grad_per_tok = p * (log_diff - kl_per_tok.unsqueeze(-1)) # (N, C, V)
grad_student = grad_per_tok * mask.unsqueeze(-1) * inv_n
return loss.to(student_logits.dtype), grad_student
In order to ensure that torch.compile correctly compiled both kernels in the same manner we profiled both variants and found that they had very similar run-time profiles showing that both methods successfully created fused forward+backward kernels.
Benchmarking Results
HuggingFace’s kernels benchmarking
The kernels repo of HuggingFace provides a benchmarking script that makes use of time.perf_counter to measure the wall-clock time of the kernel’s execution. We follow the instructions provided in their docs to leverage it for both verifying correctness and profiling. The script is located here and the core time capturing logic is as follows:
for _ in range(iterations):
start = time.perf_counter()
benchmark_fn()
_synchronize()
end = time.perf_counter()
times_ms.append((end - start) * 1000)
def benchmark_fn(func, args, warmup=20, iterations=100) -> Tuple[float, float]:
for _ in range(warmup):
func(*args)
torch.cuda.synchronize()
times = []
for _ in range(iterations):
torch.cuda.synchronize()
start = time.perf_counter()
func(*args)
torch.cuda.synchronize()
end = time.perf_counter()
times.append((end - start) * 1000)
return sum(times) / len(times), min(times)
The _synchronize() function just calls torch.cuda.synchronize() for cuda devices.
Results with kernels benchmarking
We benchmarked each of the 6 kernels against eager and torch.compile in max-autotune-no-cudagraphs mode, which we’ve found to often be the best compilation mode per our previous blog. Our kernels allocate any scratch memory at compile time and all output tensors at runtime, ensuring that we include output memory allocation time in our benchmarks. We profiled our kernels on multiple shapes and report the geometric mean of speedups across these shapes. We use a beta of 0.1 for the GRPO and BNPO kernels.
The grpo kernels were profiled on 5 shapes:
- (16, 1024)
- (32, 2048)
- (64, 4096)
- (128, 2781)
- (128, 8192)
The bnpo kernels were profiled on 6 shapes:
- (16, 1024)
- (16, 2781)
- (32, 2048)
- (64, 4096)
- (128, 2781)
- (128, 8192)
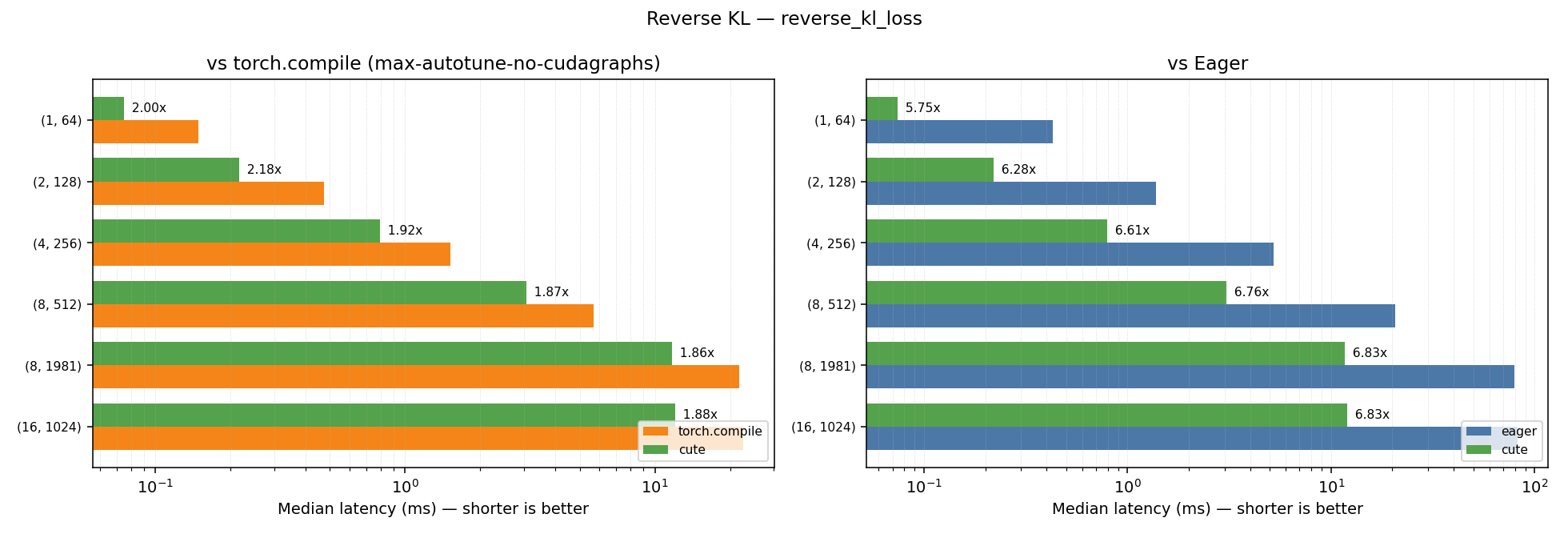
The reverse-kl kernels were profiled on 6 shapes, with a vocab size of 248320 (corresponding to Qwen3.5’s vocab size):
- (1, 64)
- (2, 128)
- (4, 256)
- (8, 512)
- (8, 981)
- (8, 1024)
The geometric-mean speedups of our cute kernels over the kernels-library baselines are summarized below; per-shape latency plots follow each table.
GRPO
| Kernel | GM Speedup vs Eager | GM Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| grpo_loss_fwd | 5.68x | 2.45x |
| grpo_loss | 20.79x | 1.98x |


BNPO
| Kernel | GM Speedup vs Eager | GM Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| bnpo_loss_fwd | 5.29x | 2.52x |
| bnpo_loss | 16.81x | 2.27x |


Reverse KL
| Kernel | GM Speedup vs Eager | GM Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| reverse_kl_fwd | 6.88x | 2.45x |
| reverse_kl | 7.03x | 2.61x |


In-house benchmarking
Internally our team has a benchmarking script that makes use of triton’s do_bench function and profiles each input shape in a completely new sub-process to avoid any caching effects from previous runs and cuda context. The GRPO and BNPO kernels need to perform extra memory accesses and flops when beta (i.e. the KL-loss coefficient) is set to a non-zero value; consequently, we profile the beta==0 and beta!=0 cases separately to show the difference in speedup when the extra compute and memory requirements are added. The results we get from our in-house benchmarking are as follows:
GRPO
GRPO with beta==0.0
| Kernel | Geometric Mean Speedup vs Eager | Geometric Mean Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| grpo_loss_fwd | 8.19x | 1.24x |
| grpo_loss | 20.65x | 1.02x |
Plots for the performance across the different shapes for the beta==0.0 case can be found below:
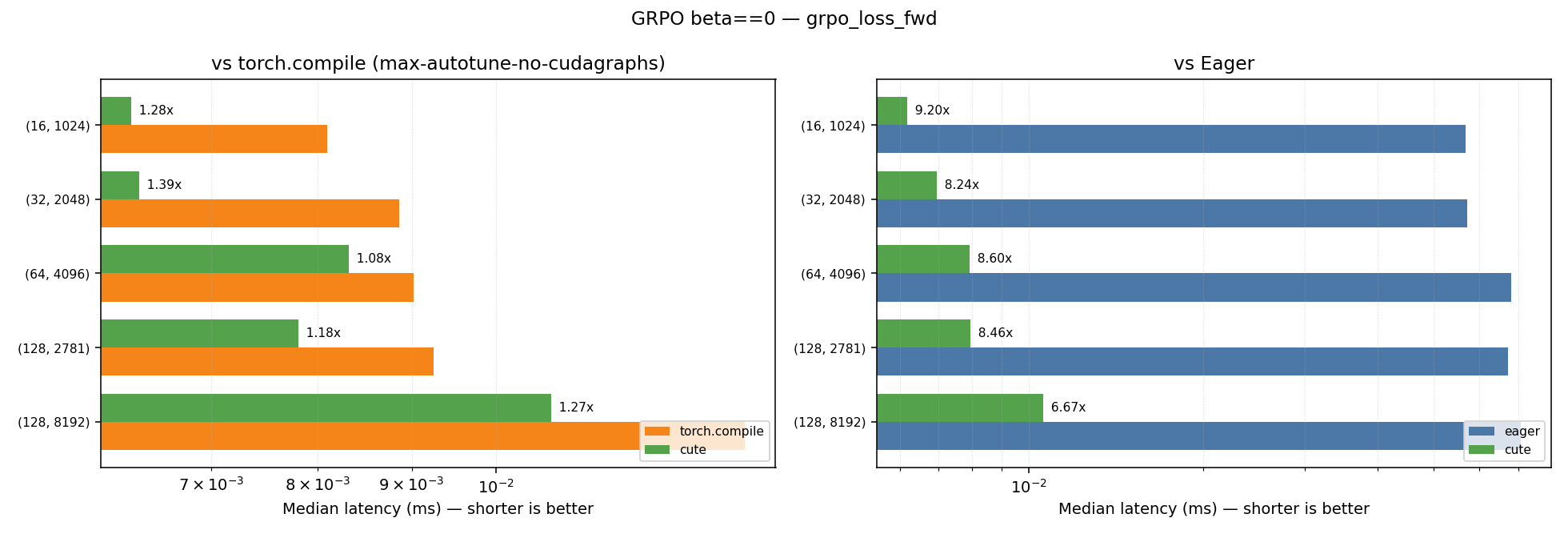
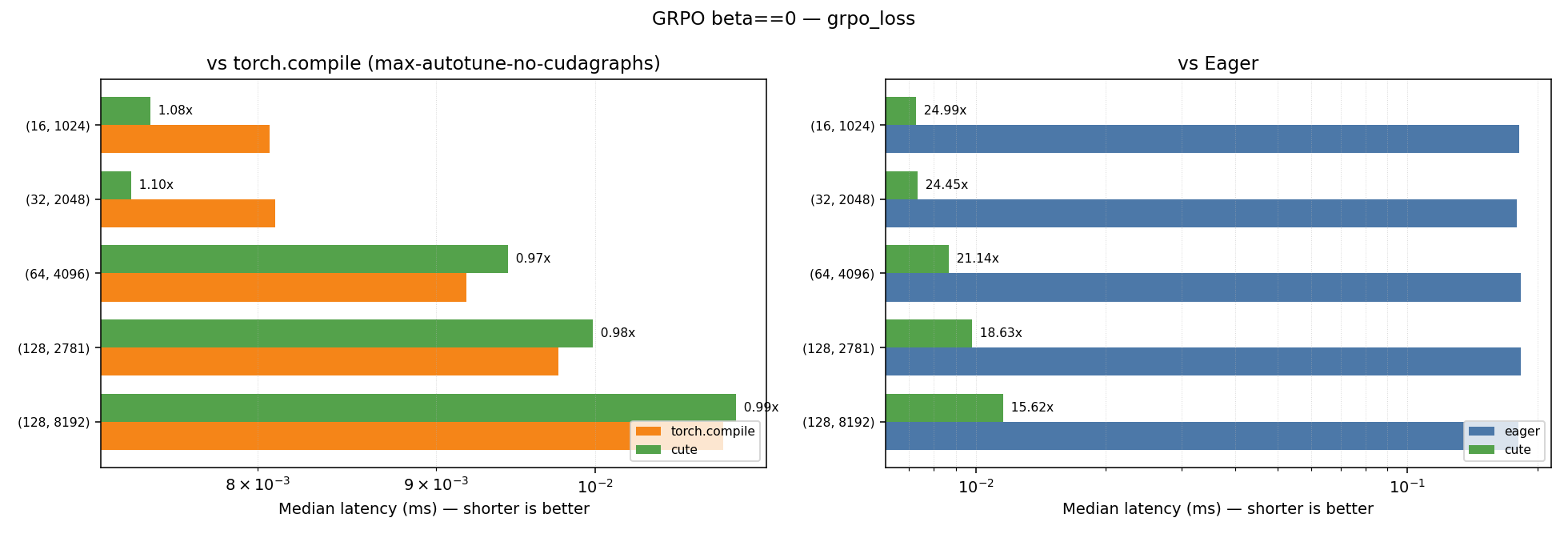
GRPO with beta!=0.0
| Kernel | Geometric Mean Speedup vs Eager | Geometric Mean Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| grpo_loss_fwd | 11.04x | 1.25x |
| grpo_loss | 27.00x | 1.08x |
Plots for the performance across the different shapes for the beta!=0.0 case can be found below:
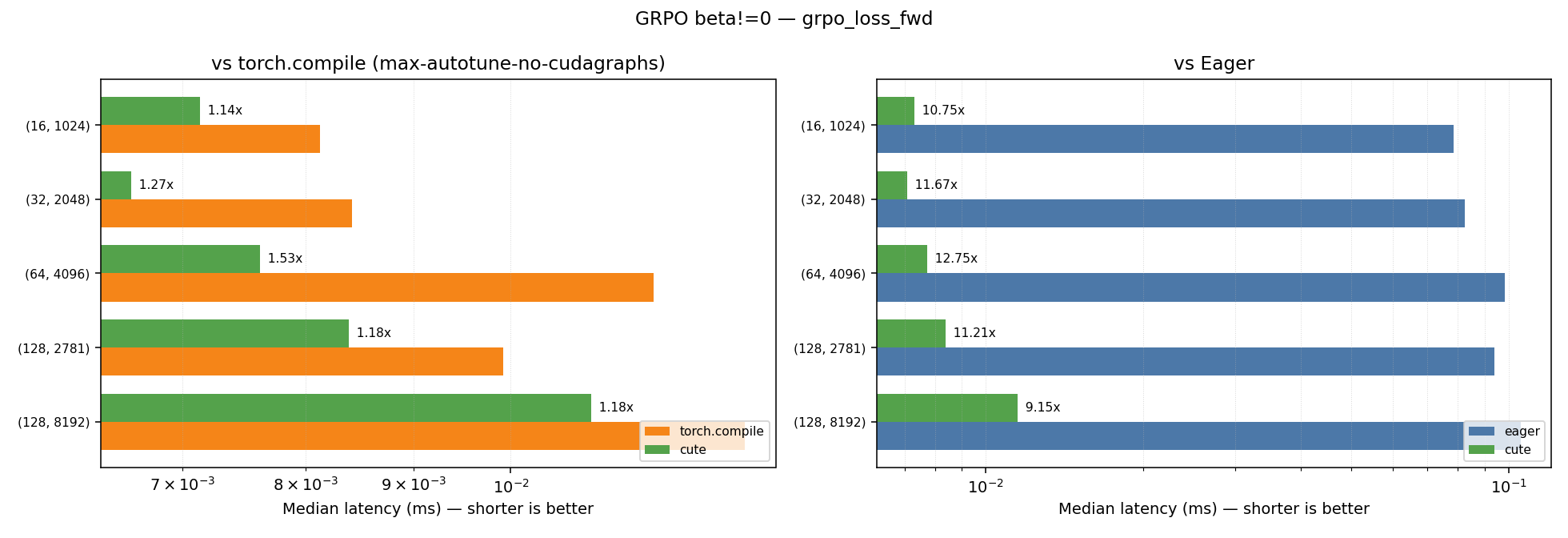
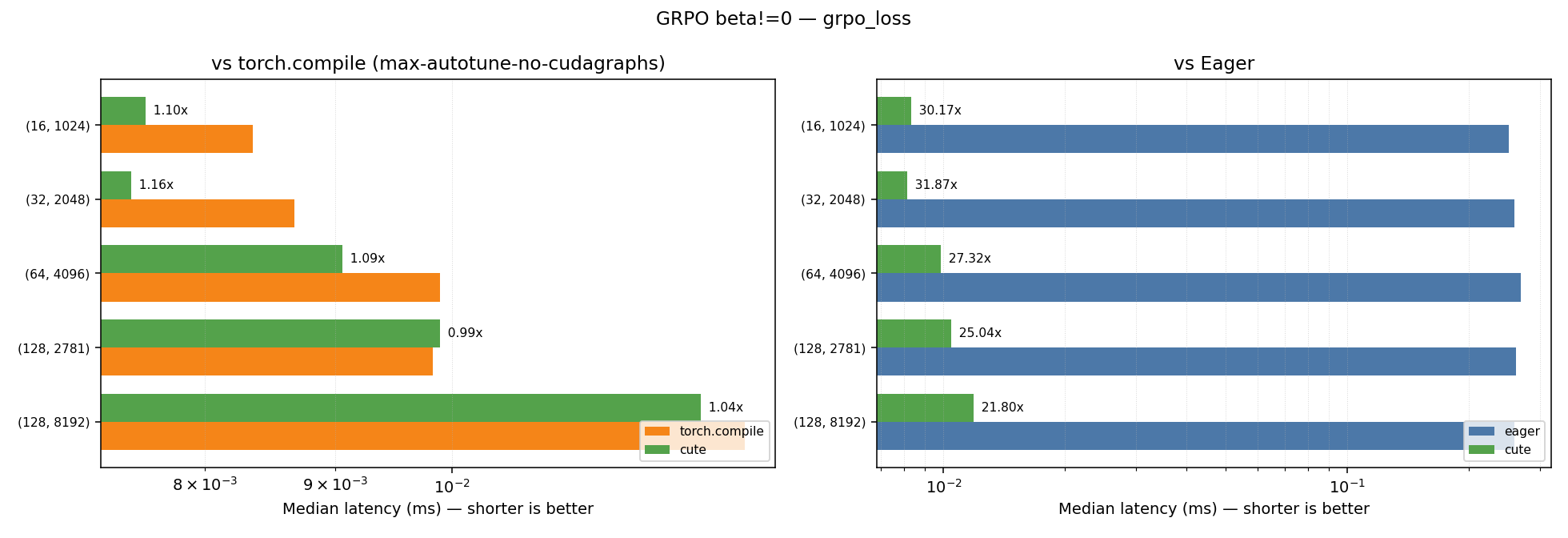
Note: Some shapes show minor regression compared to torch.compile.
BNPO
BNPO with beta==0.0
| Kernel | Geometric Mean Speedup vs Eager | Geometric Mean Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| bnpo_loss_fwd | 6.88x | 1.18x |
| bnpo_loss | 6.42x | 1.01x |
Plots for the performance across the different shapes for the beta==0.0 case can be found below:
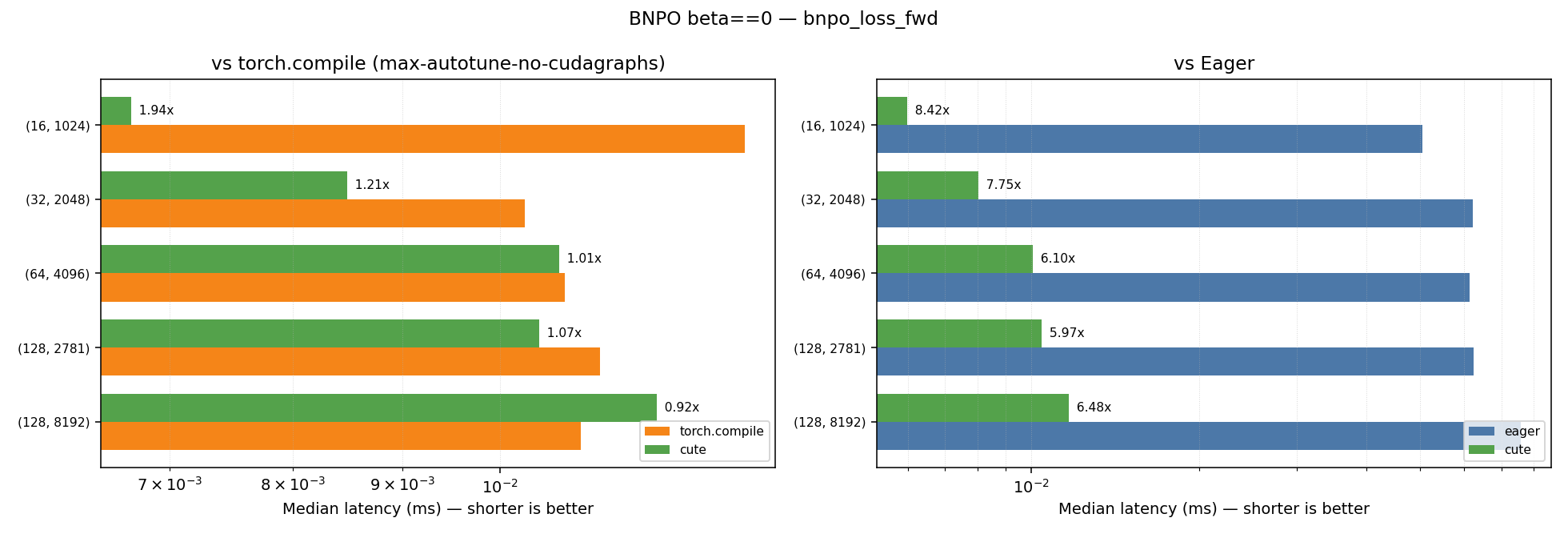
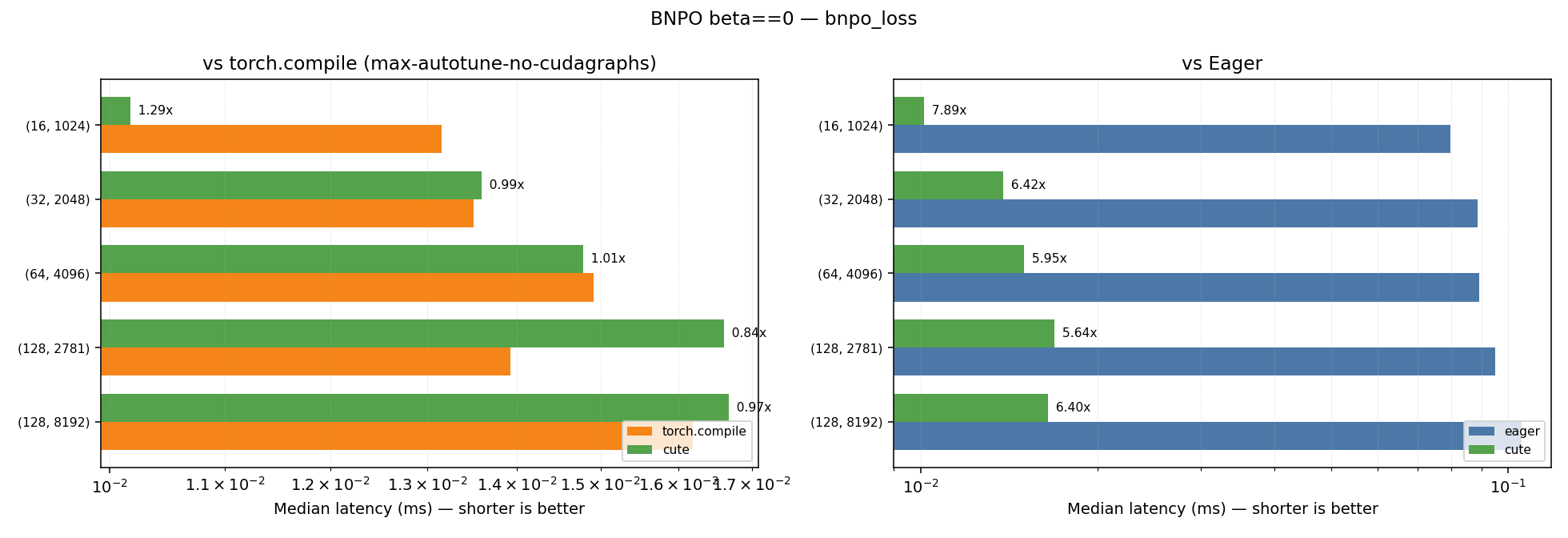
BNPO with beta!=0.0
| Kernel | Geometric Mean Speedup vs Eager | Geometric Mean Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| bnpo_loss_fwd | 9.60x | 1.31x |
| bnpo_loss | 11.02x | 1.08x |
Plots for the performance across the different shapes for the beta!=0.0 case can be found below:
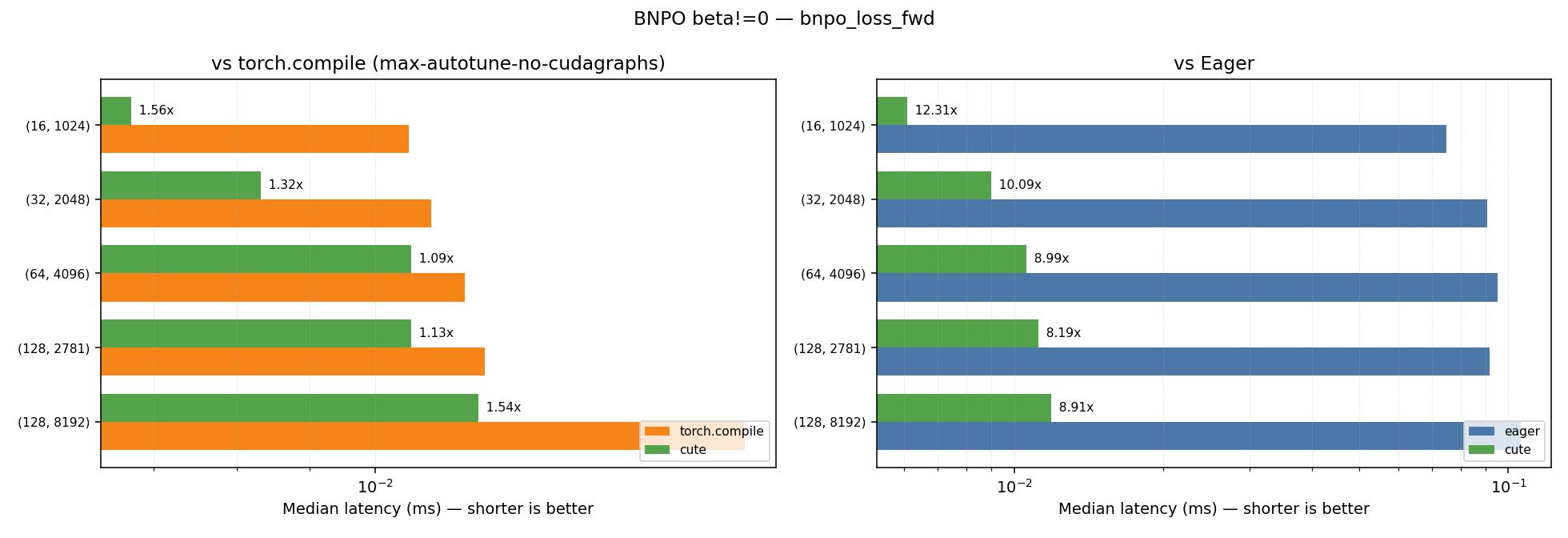
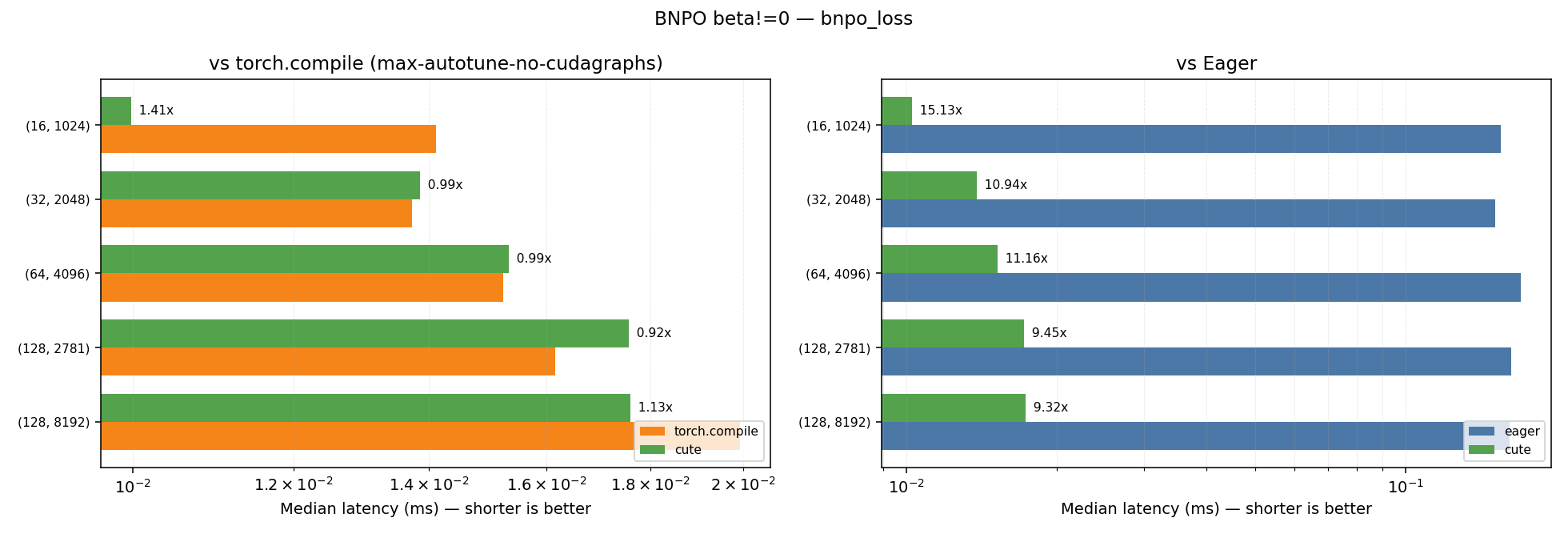
Note: Some shapes show minor regression compared to torch.compile.
Reverse KL
| Kernel | Geometric Mean Speedup vs Eager | Geometric Mean Speedup vs Torch Compile (max-autotune-no-cudagraphs) |
|---|---|---|
| reverse_kl_fwd | 7.65x | 2.57x |
| reverse_kl | 6.50x | 1.95x |
Plots for the performance across the different shapes can be found below:

Note: The kernels in our internal repo have a few structural differences with respect to their signatures and how they are wrapped compared to the ones we open-sourced, but the kernel logic is the same. We anticipate any differences in performance to be minimal. Additionally our internal repo implements the fused forward + backward kernel analytically whereas in our kernel hub release we rely on Method 1 for creating the fused forward + backward kernel, but as mentioned above we found that both methods had very similar performance.
In-house benchmarking results vs kernels benchmarking
We noticed a considerable difference in the speedups we measured with our in-house benchmarking script and the kernels benchmarking script. In general, we found that the kernels benchmarking script reported much higher speedups compared to our in-house benchmarking for the torch.compile‘d baselines. We believe that the main reasons for this are that the kernels benchmarking script:
- Doesn’t amortize the cpu-gpu synchronization cost over multiple iterations, which can lead to an overestimation of the kernel execution time, especially for very fast kernels where the synchronization overhead is a significant portion of the total time.
- Doesn’t clear the L2 cache between iterations, which can lead to an underestimation of the kernel execution time for eager and torch.compile kernels that may benefit more from caching compared to our cute kernels.
- Uses the mean execution time across iterations for the kernel being profiled instead of the median.
- Runs the reference/baseline kernel just once after warmup and uses that as the mean execution time for the baseline, which can lead to an underestimation of the baseline execution time if there is variability in the kernel execution time across iterations.
Let us know which other kernels you’d like to see open-sourced next, and if you have any feedback on the kernels we released! You can either drop a comment below or reach us on LinkedIn @GeometricAI.